«AMD» سالها است از نظر کارایی در حوزه معماری x86 پشت سر Intel قرار گرفته است. از زمان معرفی اولین پردازنده Core 2 در سال 2006، AMD هیچگاه نتوانست روزهای خوش پردازندههای Athlon 64 و Athlon 62 X2 را تکرار کند. اما در عوض با کاهش قیمتها و رقابتی وسیع در محدوده ریزپردازندههای زیر 200 دلار، جایگاه خود را حفظ کرد. این استقامت AMD بیشتر مدیون استراتژی «هستههای بیشتر در ازای قیمت کمتر» بود. AMD به خاطر قیمتگذاریهای هوشمندانه بر روی اجزای 3 و 6 هستهای، برای کسانی که نیاز به تعداد زیادی هسته داشتند، ارزشمندتر از گذشته شد.
در این مقاله سعی می کنیم که با تشریح معماری پردازنده نسل جدید، برتری ها و قابلیت های جدید آن را بررسی کنیم. همچنین یادآور می شویم که از اصطلاحات تخصصی زیادی استفاده شده و مطالب دارای سطح علمی متوسط و پیشرفته می باشند و تلاش شده در ابتدای بکار بردن هر اصطلاح جدید توضیح مختصری نیز در رابطه با آن عنوان شود، اما خوانندگانی که تجربه و اطلاعات محدودی دارند نیز می توانند برای اطلاع از نتایج بررسیها به بخش “عملکرد در بازیها” مراجعه کنند.
سری پردازندههای FX,«AMD» سالها است از نظر کارایی در حوزه معماری x86 پشت سر Intel قرار گرفته است. از زمان معرفی اولین پردازنده Core 2 در سال 2006، AMD هیچگاه نتوانست روزهای خوش پردازندههای Athlon 64 و Athlon 62 X2 را تکرار کند. اما در عوض با کاهش قیمتها و رقابتی وسیع در محدوده ریزپردازندههای زیر 200 دلار، جایگاه خود را حفظ کرد. این استقامت AMD بیشتر مدیون استراتژی «هستههای بیشتر در ازای قیمت کمتر» بود. AMD به خاطر قیمتگذاریهای هوشمندانه بر روی اجزای 3 و 6 هستهای، برای کسانی که نیاز به تعداد زیادی هسته داشتند، ارزشمندتر از گذشته شد.
با این وجود، اخیرا Intel توانست کارایی هر هسته را با عرضه Sandy Bridge بالاتر ببرد، بدین ترتیب هرچه تعداد هستهها بیشتر میشود، توصیه کردن پردازندههای معادل خانواده AMD هم سخت تر میشود. از طرفیAMD سعی میکند که برای کسب اعتبار، توجه کاربران را به عملکرد خوب پردازندههای خود در برنامههای Single Threaded معطوف کند اما این کار فروش کامپیوترهای Desktop پرقدرت را سخت تر میکند. مدتی است که AMD به یک انقلاب در معماری پردازندهها نیاز دارد تا بتواند به بازار کامپیوترهای پرقدرت تسلط پیدا کند و از طرفی کمبودهای مشتریان کامپیوترهای معمولی را یادآوری کند. اینک پس از انتظاری طولانی، به آن معماری جدید رسیدهایم؛ خانمها و آقایان، «بولدوزر» آمده است. (لقب پردازشگرهای نسل بعد AMD),معرفی , ,نام تجاری این پردازنده AMD FX است و فقط روی حالت تک die عرضه میشود. «بولدوزر» با مساحت 315 میلیمتر مربعی و وزنی که حاصل از 2 میلیارد ترانزیستور (تقریبا هماندازه یک کارت گرافیک) است (البته AMD رقم 2 میلیارد ترانزیستور را به 1.2 میلیارد کاهش داد)، چندان از طرح پردازنده 45 نانومتری Phenom II شش هستهای، کوچکتر نیست؛ هرچند براساس فرآیند عایقهای 32 نانومتری سیلیکونی شرکت Global Foundries ساخته شده است. هم مساحت و هم تعداد ترانزیستور بهطور چشمگیری بیشتر از sandy bridge هستند، در حالیکه که پردازش HKMG 32 نانومتری اینتل تنها با 995 میلیون ترانزیستور در مساحت 216 میلیمتر مربعی صورت میپذیرد. پس این یک تراشه بزرگ است.,
,نام تجاری این پردازنده AMD FX است و فقط روی حالت تک die عرضه میشود. «بولدوزر» با مساحت 315 میلیمتر مربعی و وزنی که حاصل از 2 میلیارد ترانزیستور (تقریبا هماندازه یک کارت گرافیک) است (البته AMD رقم 2 میلیارد ترانزیستور را به 1.2 میلیارد کاهش داد)، چندان از طرح پردازنده 45 نانومتری Phenom II شش هستهای، کوچکتر نیست؛ هرچند براساس فرآیند عایقهای 32 نانومتری سیلیکونی شرکت Global Foundries ساخته شده است. هم مساحت و هم تعداد ترانزیستور بهطور چشمگیری بیشتر از sandy bridge هستند، در حالیکه که پردازش HKMG 32 نانومتری اینتل تنها با 995 میلیون ترانزیستور در مساحت 216 میلیمتر مربعی صورت میپذیرد. پس این یک تراشه بزرگ است.,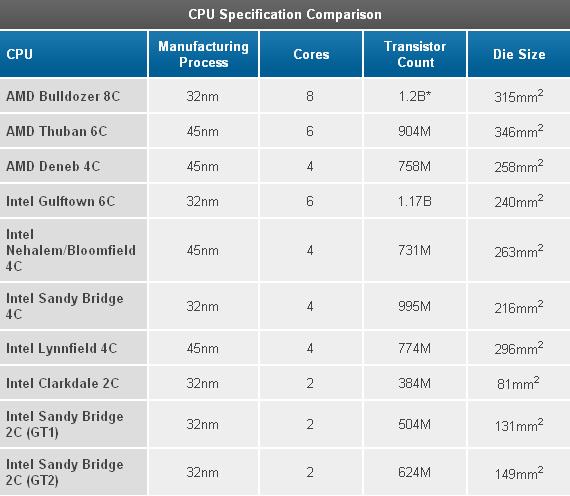 ,از دید معماری، «بولدوزر» از همه چیزهایی که تا به حال دیدهایم، انقلابیتر است. ما بعدا بیشتر وارد جزئیات میشویم، اما همینقدر بدانیم که واحد ساختاری AMD در این معماری Bulldozer module یا «ماژول بولدوزر» است. هر ماژول از یک هسته integer یا «اعداد صحیح» به اضافه یک هسته FP یا «واحد ممیز شناور» مشترک ساخته میشود. با این که سختافزار FP بزرگتر است ولی تاکنون کمتر در کامپیوترهای رومیزی (و عملیات سرور) استفاده شده است. پس AMD تصمیم گرفت تا به جای ارائه نسبت 1 به 1 بین هستههای integer و FP آن را بین 2 هسته «بولدوزر» تقسیم کند. اعلام شده که تفاوت «بولدوزر» و قطعات سری FX بر تعداد هستههای integer میباشد. پس یک قطعه چهار ماژوله FX با 8 هسته integer یک «پردازنده 8 هستهای» نام گرفته است.,
,از دید معماری، «بولدوزر» از همه چیزهایی که تا به حال دیدهایم، انقلابیتر است. ما بعدا بیشتر وارد جزئیات میشویم، اما همینقدر بدانیم که واحد ساختاری AMD در این معماری Bulldozer module یا «ماژول بولدوزر» است. هر ماژول از یک هسته integer یا «اعداد صحیح» به اضافه یک هسته FP یا «واحد ممیز شناور» مشترک ساخته میشود. با این که سختافزار FP بزرگتر است ولی تاکنون کمتر در کامپیوترهای رومیزی (و عملیات سرور) استفاده شده است. پس AMD تصمیم گرفت تا به جای ارائه نسبت 1 به 1 بین هستههای integer و FP آن را بین 2 هسته «بولدوزر» تقسیم کند. اعلام شده که تفاوت «بولدوزر» و قطعات سری FX بر تعداد هستههای integer میباشد. پس یک قطعه چهار ماژوله FX با 8 هسته integer یک «پردازنده 8 هستهای» نام گرفته است.,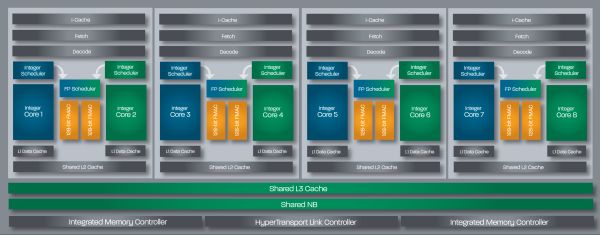 ,تا به حال 7 پردازنده از سری FX معرفی شده هرچند تنها 4 تای آنها بهزودی عرضه خواهند شد.,
,تا به حال 7 پردازنده از سری FX معرفی شده هرچند تنها 4 تای آنها بهزودی عرضه خواهند شد.,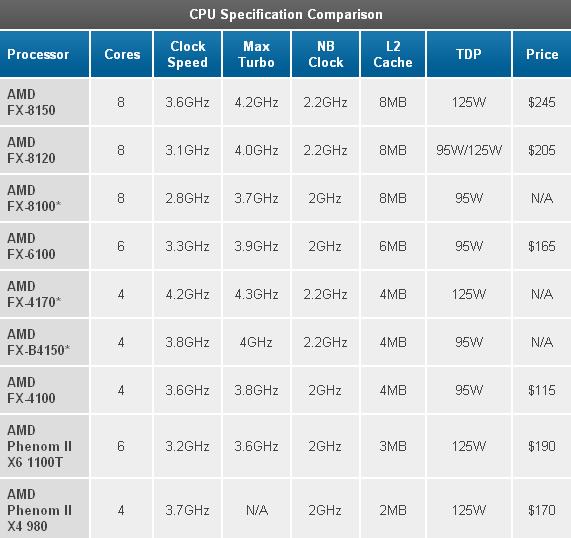 ,معرفی پردازنده بولدوزر,پردازندههای FX-8150، 8120، 6100 و 4100 آنهایی هستند که به تازگی عرضه شدهاند. اولین رقم از این شمارهها نشانگر تعداد هستههای پردازنده است، برای مثال در حالی که 8120 و 8150 با نشان دادن 8 هسته خودنمایی میکنند، 6100 تنها 6 هسته فعال دارد. L2 Cache (حافظه پنهان سطح 2) متناسب با تعداد هستهها مشخص میشود (2 مگابایت در هر ماژول) درحالی که Cache سطح 3 صرف نظر از SKU روی 8 مگابایت ثابت میماند.
,معرفی پردازنده بولدوزر,پردازندههای FX-8150، 8120، 6100 و 4100 آنهایی هستند که به تازگی عرضه شدهاند. اولین رقم از این شمارهها نشانگر تعداد هستههای پردازنده است، برای مثال در حالی که 8120 و 8150 با نشان دادن 8 هسته خودنمایی میکنند، 6100 تنها 6 هسته فعال دارد. L2 Cache (حافظه پنهان سطح 2) متناسب با تعداد هستهها مشخص میشود (2 مگابایت در هر ماژول) درحالی که Cache سطح 3 صرف نظر از SKU روی 8 مگابایت ثابت میماند.
فرکانس چیپست پل شمالی (North Bridge) و Cache سطح 3 بین 2.0 گیگاهرتز و 2.2 گیگاهرتز متناوب است. همچنین دامنه TDP (توان طراحی حرارتی) بین 95 وات تا 125 وات قرار دارد و FX-8120 در هر دو ورژن 125 وات و 95 وات ارائه میشود.
طرح ساخت «بولدوزر» یکتا است. مدلهای 4 و 6 هستهای در واقع از هستههای غیرفعال شده طرح اصلی تشکیل شدهاند. البته AMD اذعان کرده است که دیگر آنلاک کردن هستهها در قطعات این طرح، امکان پذیر نخواهد بود.
از طرفی شکاف بزرگ در سرعت clock بین پردازندههای 8150 و 8120 نگران کننده است. معمولا شیب تغییرات فرکانس ثابت است اما در عمل تفاوت 16 درصدی بین دو SKU، نشانگر مشکلات ساخت پردازنده در فرکانسهای بالا و محدود بودن میزان پردازش است. حداقل در نسخه 8 هستهای که اینچنین است.
بدون در نظر گرفتن قلب 4 و 6 هستهای «بولدوزر»، تنها پردازنده از سری FX که میتواند سرعت کلاک 3.3 گیگاهرتزی پردازنده Phenom II X6 1100T را پشت سر بگذارد، 8150ّFX- است. حال اگر قطعات 4 هستهای Phenom II را به حساب بیاوریم، میبینیم که تنها 2 قطعه از «بولدوزر» با سرعت بیشتری از Phenom II X4 980 عرضه میشوند. هرچند تایید شده است که با کمک Turbo core فرکانس بالاتر میرود، اما این فرکانسهای پایه کم، مشکلساز هستند. برای یک معماری که قرار بود سرعت کلاک پیشینیان خود را 30% بالاتر ببرد، به نظر نمیرسد که «بولدوزر» حتی نزدیک آن سطح هم شده باشد.
در ضمن باید بدانیم که تمامی پردازندههای سری FX، آنلاک شده بفروش میرسند،در نتیجه Overclock کردن آنها بسیار راحتتر شده است.,سازگاری با مادربورد,AMD مشخص کرد که سری FX تنها بر روی مادربوردهای Socket-AM3+ استفاده میشود. با این وضعیت، دارندگان مادربوردهای استاندارد AM3 ممکن است کمی بدشانس باشند، اگرچه شرکتهای سازنده مادربرد میتوانند بردهای خود را برای استفاده بولدوزر آماده کنند. بههرحال AMD تنها از مادربوردهای AM3+ که قابلیت پشتیبانی از BIOS/UEFI هم دارند، رسما پشتیبانی میکند., ,تمامی خنک کنندههای AM2/AM2+/AM3/AM3+ با پردازندههای FX کار میکنند، اما براساس مقدار TDP اولویتها کمی فرق میکند.,
,تمامی خنک کنندههای AM2/AM2+/AM3/AM3+ با پردازندههای FX کار میکنند، اما براساس مقدار TDP اولویتها کمی فرق میکند., ,برای نوشتن این نقد، AMD مادربورد ASUS’ Crosshair V Formula AM3+ که مخصوص چیپست 990FX خودش طراحی شده بود، را برای نویسنده فراهم کرد.
,برای نوشتن این نقد، AMD مادربورد ASUS’ Crosshair V Formula AM3+ که مخصوص چیپست 990FX خودش طراحی شده بود، را برای نویسنده فراهم کرد.
AMD شش درگاه SATA با سرعت 6Gb/sبرای چیپست 990FX تعبیه کرده، که نسبت به دو درگاه مرسوم سری 6 اینتل، یک قدم رو به جلوی بسیار بزرگ حساب میشود. همچنین در «بولدوزر» الگوریتم تصحیح خطای حافظه Unbuffered ECC برای کسانی که امنیت بیشتری میخواهند، قابل استفاده شده است؛ این یکی دیگر از قابلیتهایی است که در چیپستهای سری 6 از Intel پشتیبانی نشده بود.,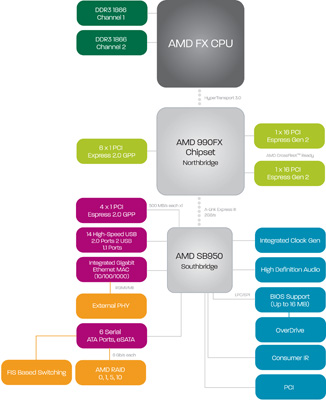 ,با این که تمایل AMD به سمت عرضه تکنولوژی مجمتع کردن APUها با GPU است (البته یک socket جدید نیاز دارد) اما همچنان تاکید میکند که پلتفرم AM3+ میتواند قبل از بازنشسته شدن، یک نسل دیگر از این پردازندهها را به چشم ببیند.,سیستم خنک کننده مایع AMD,در کنار سری پردازندههای FX، شرکت AMD یک سیستم خنک کننده مایع کاملا جدید (که ساخت Asetek میباشد) را نیز معرفی میکند.,
,با این که تمایل AMD به سمت عرضه تکنولوژی مجمتع کردن APUها با GPU است (البته یک socket جدید نیاز دارد) اما همچنان تاکید میکند که پلتفرم AM3+ میتواند قبل از بازنشسته شدن، یک نسل دیگر از این پردازندهها را به چشم ببیند.,سیستم خنک کننده مایع AMD,در کنار سری پردازندههای FX، شرکت AMD یک سیستم خنک کننده مایع کاملا جدید (که ساخت Asetek میباشد) را نیز معرفی میکند., ,این سیستم خنک کننده AMD شبیه به مدل شرکتهایی چون Antec و Corsair است. دستگاه کاملا مستقل میباشد و نیازی نیست که نگران کم شدن مایع درون آن باشید. (زیرا یک چرخه بسته دارد)
,این سیستم خنک کننده AMD شبیه به مدل شرکتهایی چون Antec و Corsair است. دستگاه کاملا مستقل میباشد و نیازی نیست که نگران کم شدن مایع درون آن باشید. (زیرا یک چرخه بسته دارد)
برای نصب کردن کافی است ماژول خنک کننده را با یک bracket به socket پردازنده و رادیاتور را به کیس خود وصل کنید. رادیاتور با 2 فن 120 میلیمتری (که در جعبه قرار داده شده است) خنک میشود.
, ,AMD هنوز نظر خاصی بر روی قیمت یا در دسترس بودن مایع خنک کننده مخصوص ندارد، اما انتظار داریم که قیمت آن حدود 100 دلار باشد.
,AMD هنوز نظر خاصی بر روی قیمت یا در دسترس بودن مایع خنک کننده مخصوص ندارد، اما انتظار داریم که قیمت آن حدود 100 دلار باشد.
,چشمانداز,برای اولین بار، AMD به برنامههای بلندمدت خود نزدیک شده است. چند روز پیش، AMD چشمانداز 4 سال آینده پردازشگرهای خود را منتشر نمود. نام این پردازشگرها با کدهای شناسایی، در عکس زیر آمده اند:,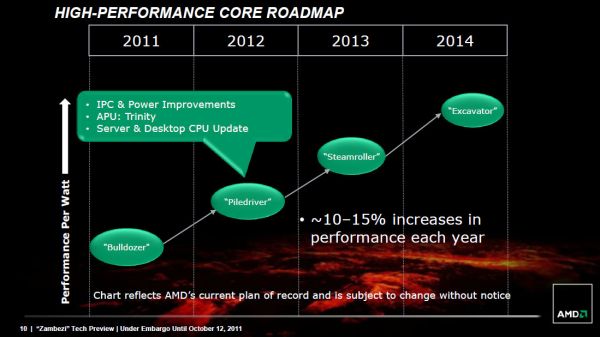 ,«Piledriver» همانطور که میدانید، دارای پردازشگر Trinity است،APU یی با دو تا چهار هسته که در اوایل سال 2012 وارد بازار خواهد شد. عملکرد پردازندههای سری «Piledriver» نسبت به «بولدوزر» 10 تا 15 درصد بالاتر خواهد بود، هرچند در ابتدا، روند خود را آرام شروع خواهد کرد. آیا به یاد دارید که این نسل را آخرین نسل پردازندههای AM3+ خواندیم؟ کاملا منتظر معرفی یک نسخه بدون GPU در سال 2012 هستیم.
,«Piledriver» همانطور که میدانید، دارای پردازشگر Trinity است،APU یی با دو تا چهار هسته که در اوایل سال 2012 وارد بازار خواهد شد. عملکرد پردازندههای سری «Piledriver» نسبت به «بولدوزر» 10 تا 15 درصد بالاتر خواهد بود، هرچند در ابتدا، روند خود را آرام شروع خواهد کرد. آیا به یاد دارید که این نسل را آخرین نسل پردازندههای AM3+ خواندیم؟ کاملا منتظر معرفی یک نسخه بدون GPU در سال 2012 هستیم.
سری «Steamroller» در سال 2013 خواهد آمد، و باز هم با افزایش کارایی (احتمالا در تعداد و سطح هستهها) 10 تا 15 درصدی همراه خواهد بود. سری«Excavator» هم همین کار را در سال 2014 تکرار خواهد کرد. AMD عقیده دارد که این کارآمدتر کردنها برای همپا جلو آمدن با Intel کافی است، اما برای قضاوت زود است و باید ببینم آمار بررسی «بولدوزر» چه اطلاعاتی به ما میدهد.
نکته مهم دیگر در باره چشمانداز AMD این است که همزمان با قرار دادن شرکت در یک ریتم سالیانه تجاری، تعامل خود را با بخش GPU آنها هم حفظ میکند. با این که AMD درباره مشکلات سر راه پردازندههای خود صحبت نمیکند، اما به نظر میرسد که AMD بالاخره جوابی برای رقابت با زمانبندی معروف Tick -Tock شرکت Intel برای معرفی پردازنده ها پیدا کرده است.
,معماری,معماری بولدوزر,ما، طبق رسم همیشگی، قصد داریم که نقد خود را از بخش Front end (قسمت کوچکی که وظیفهاش برقراری ارتباط با host یا وسایل جانبی است) «بولدوزر» شروع کنیم. در «بولدوزر»، واحد منطق «اخذ و رمزگشایی» در هر ماژول بین 2 هسته Integer به اشتراک گذاشته شده است. وظیفه این واحد منطق شامل گرفتن دستورات بعدی Thread یا بند در حال اجرا(کوچکترین واحد پردازشی داده ها که قابل زمانبندی توسط سیستم عامل باشد)، رمزگشایی دستورات x86 به فرمت داخلی AMD و سپس واگذار کردن آنها به سختافزار تعیین شده برای اجرا است.
در «بولدوزر» AMD بخش Front end «سری K8» را عریض تر از گذشته کرده است. حال هر ماژول میتواند همزمان عملیات اخذ و رمزگشایی را برای 4 دستور x86 موجود در یک Thread، انجام دهد و این کار را بدون کاهش ذرهای از قدرت رمزگشایی آنها عملی میکند. از طرفی باید به یاد داشته باشیم که این ماژولی که ما از آن سخن میگوییم، نمایانگر دو هسته است. تک تک ماژولهای «بولدوزر» میتوانند همگام با سرعت کلاک بین Threadها جابجا شوند.,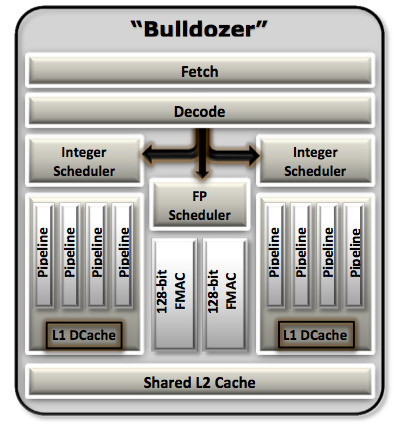 ,سختافزار رمزگشایی بخودی خود چندان هم ارزشمند نیست اما اگر همین اندازه را به ازای هر هسته، 4 برابر کنیم،اهمیت آن بسیار زیاد میشود. با این که عرض واحد رمزگشایی تک هستهها بیشتر شده است، اما ترکیب چند هستهای آن در واقع یک پسرفت نسبت به معماریهای قبلی داشته است. بیایید دلیلش را در جدول زیر جستوجو کنیم:,
,سختافزار رمزگشایی بخودی خود چندان هم ارزشمند نیست اما اگر همین اندازه را به ازای هر هسته، 4 برابر کنیم،اهمیت آن بسیار زیاد میشود. با این که عرض واحد رمزگشایی تک هستهها بیشتر شده است، اما ترکیب چند هستهای آن در واقع یک پسرفت نسبت به معماریهای قبلی داشته است. بیایید دلیلش را در جدول زیر جستوجو کنیم:,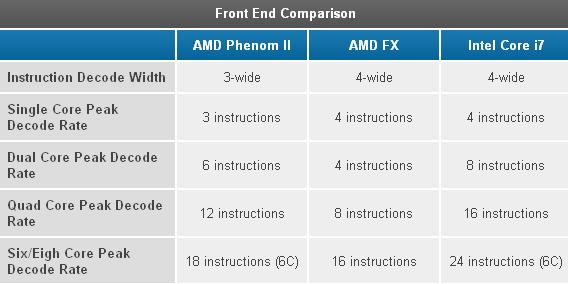 ,اگر دیدمان را محدود به یک Thread تک دستورالعملی کنیم، میبینیم که پهنای باند Front end «بولدوزر» نسبت به پیشینیانش بیشتر شده. با این که Front end قویتر شده، اما توجه کنید چه اتفاقی خواهد افتاد اگر تعداد هسته ها را افزایش دهیم.
,اگر دیدمان را محدود به یک Thread تک دستورالعملی کنیم، میبینیم که پهنای باند Front end «بولدوزر» نسبت به پیشینیانش بیشتر شده. با این که Front end قویتر شده، اما توجه کنید چه اتفاقی خواهد افتاد اگر تعداد هسته ها را افزایش دهیم.
علی رغم این که هر ماژول، واحد «منطق اخذ و رمزگشایی» دارد و AMD هر ماژول را 2 هسته به حساب میآورد و هستهها کاملا یکسان هستند، باز هم Phenom II قدیمی سریعتر از FX عمل اخذ/رمزگشایی را انجام میدهد. تئوری AMD این است که شرایطی که در آن محدودیت مرحله Fetch/Decode وجود دارد آنقدر کم پیش می آید که به اشتراک گذاری سخت افزار را توجیه می کند. بسیاری از دستورات ممکن است چندین چرخه را برای رمزگشایی طی کنند؛ جابجایی هر چرخه بین Thread ها باعث میشود که عملیات Front end بهتر بهینهسازی شود. خیلی دردناک است که Front end قوی، خود به یک عامل محدود کننده تبدیل شود.
از دید بالاتر، مقایسه معماری FX با معماری Core از Intel نشان میدهد که AMD در اینجا در موضع ضعف است. در لیست محصولات High-end، جایی که Intel با Hyper threading پا به میدان گذاشته است، AMD هیچ مهرهای ندارد که بتواند مثل Intel در هر کلاک، دو دستور را با هم اجرا کند. حتی اگر با محصولات قبلی Intel (که Hyper Threading نداشته اند) هم مقایسه کنیم، باز هم مشخص نیست که کدام یک از پردازندهها پیشی گرفته است. Intel توانسته است که در هر کلاک و در هر لحظه، با قدرت بیشتری رمزگشایی کند، هرچند ممکن است به خاطر ناتوانی در اخذ دادهها از صفهای متعدد، کمی لطمه ببیند.
بعد از اعمال تغییر در واحد رمزگشایی، AMD به سراغ عملیات مخصوصی رفت و آنها را با هم ترکیب کرد تا به عنوان یک عملیات مسنجم و مستقل عمل کنند. دقیقا شبیه همان کاری که Intel با تکنیک Micro Ops Fusion خود انجام داد و برای اولین بار در سال 2003 در پردازنده Banias به کار برد. عملیات مقایسه-انشعاب (= branch = دستورالعملی که به کامپیوتر میگوید که به قسمت دیگر برنامه پرش کند) و آزمایش-انشعاب و چندین عملیات دیگر میتوانند در «بولدوزر» با هم ترکیب شوند و کارایی بخش back end را افزایش دهند. این قابلیت در Phenom II امکان پذیر نبود و قطعا میزان IPC (روشهای مبادله داده بین چندین بند یا Thread ) را بالاتر میبرد.,یک branch predictor مستقل,AMD هنوز اطلاعات زیادی از ساختار سخت افزار «branch predictor» (یک واحد که مسیر انشعابها را حدس میزند) در «بولدوزر» فاش نکرده اما بد نیست به یک پیشرفت مهم اشاره کنیم: از این به بعد branch predictor کاملا مستقل از Front end عمل میکند.,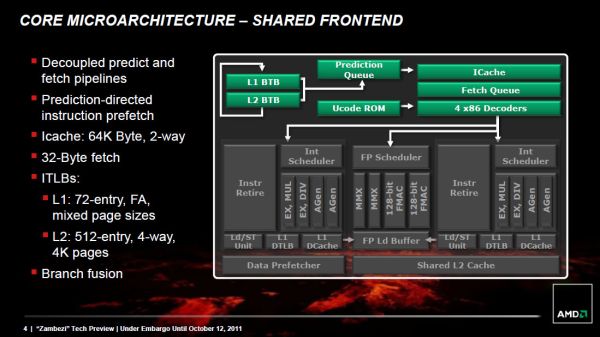 ,نقش branch predictor این است که دستورات انشعاب را قطع کند و هدف آنها را پیشگویی کند و تا وقتی که هدف شاخه مشخص نشده، به چرخهها اجازه فعالیت نمیدهد. واضح است که دقت پیشگوییهای branch predictor مستقیما به تعداد دادهها و آمادگی این سختافزار برای آن حجم از دادهها بستگی دارد. دقت branch predictor بسیار برای معماری حائز اهمیت است زیرا یک پیشگویی اشتباه در معماریهایی که pipeline (از عوامل فرآیند پردازش دادهها که به هم سری بسته شدهاند و خروجی یک عنصر را ورودی عنصر بعدی قرار میدهند) پیچیده دارند، باعث میشود که دستورات زیادی از چرخه پردازش خارج شوند. افزایش عمق pipelineهای «بولدوزر» این پیشرفتهای branch predictor را ضروری کرده بود.
,نقش branch predictor این است که دستورات انشعاب را قطع کند و هدف آنها را پیشگویی کند و تا وقتی که هدف شاخه مشخص نشده، به چرخهها اجازه فعالیت نمیدهد. واضح است که دقت پیشگوییهای branch predictor مستقیما به تعداد دادهها و آمادگی این سختافزار برای آن حجم از دادهها بستگی دارد. دقت branch predictor بسیار برای معماری حائز اهمیت است زیرا یک پیشگویی اشتباه در معماریهایی که pipeline (از عوامل فرآیند پردازش دادهها که به هم سری بسته شدهاند و خروجی یک عنصر را ورودی عنصر بعدی قرار میدهند) پیچیده دارند، باعث میشود که دستورات زیادی از چرخه پردازش خارج شوند. افزایش عمق pipelineهای «بولدوزر» این پیشرفتهای branch predictor را ضروری کرده بود.
مانند Phenom II، شاخهها و سختافزار اخذ در Front end قرار گرفتهاند. هرچند در Phenom II کوچکترین تاخیر در قسمت اخذ داده (به طور مثال، اخذ دادهای که داخل Cache وجود نداشته است) باعث میشد که کل pipeline –که branch predictor هم جزوی از آن است- از کار بیفتد. به همین دلیل، «بولدوزر» branch predictor را از قسمت اخذ (fetch pipeline) جدا کرده است. بدین ترتیب، اگر هرگونه تاخیری در فرآیند اخذ صورت گیرد، branch predictor اجازه دارد که به کارش ادامه دهد و پیشبینیهای بعدی خود را انجام دهد تا صف دادهها پر شود.,پیشرفت واحدهای Scheduling و Execution,همزمان با معرفی Sandy Bridge توسط Intel، شرکت AMD هم با «بولدوزر» به نوع جدیدی از register (حافظه کوچکی که قسمتی از دادههای موقت کامپیوتر در آن ذخیره میشود) فیزیکی مهاجرت کرد. حال دادهها فقط در یک register فیزیکی ذخیره میشوند و به وسیله Pointerها(متغیرهایی که دادهها را به متغیرهای دیگر ارجاع میدهند) به PRF مشایعت میشوند و همزمان دیگر عملیاتها نیز در engine Execution به مسیر خود ادامه میدهند. این تغییرات فقط برای جلوگیری از به هدر رفتن توان کامپیوتر در عملیاتی مثل Copy کردن است.,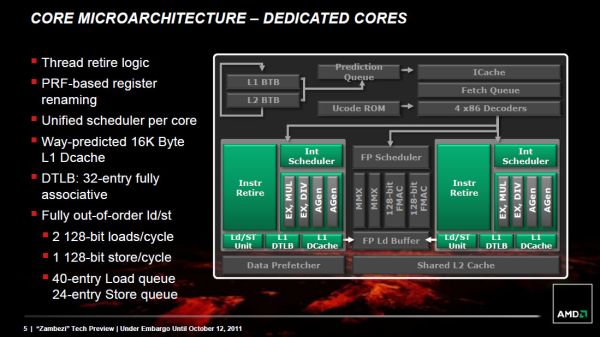 ,متاسفانه علی رغم اینکه AMD از جانب سختافزار issue (یک واحد از کار است که در صورت انجام به بهبود عملکرد سیستم نرمافزاری منجر میشود) قدم رو به جلوئی برداشته است اما وقتی به Execute کردن منابع خودش میرسد کمی دچار اشتباه میشود. میخواهیم یکی دیگر از نقاط قوت «بولدوزر» را معرفی کنیم: هستههای integer execution,Integer Execution,همانطور که پیشتر گفتیم هر ماژول «بولدوزر» از دو هسته integer کاملا مستقل تشکیل شده است. هر یک از هستهها یک integer scheduler مخصوص برای ذخیره پروندهها و حافظه 16 کیلوبایتی سطح L1 دارد و جالب است بدانید که هر دو نسبت به قطعات مشابه در Phenom II بزرگتر شدهاند.,
,متاسفانه علی رغم اینکه AMD از جانب سختافزار issue (یک واحد از کار است که در صورت انجام به بهبود عملکرد سیستم نرمافزاری منجر میشود) قدم رو به جلوئی برداشته است اما وقتی به Execute کردن منابع خودش میرسد کمی دچار اشتباه میشود. میخواهیم یکی دیگر از نقاط قوت «بولدوزر» را معرفی کنیم: هستههای integer execution,Integer Execution,همانطور که پیشتر گفتیم هر ماژول «بولدوزر» از دو هسته integer کاملا مستقل تشکیل شده است. هر یک از هستهها یک integer scheduler مخصوص برای ذخیره پروندهها و حافظه 16 کیلوبایتی سطح L1 دارد و جالب است بدانید که هر دو نسبت به قطعات مشابه در Phenom II بزرگتر شدهاند.,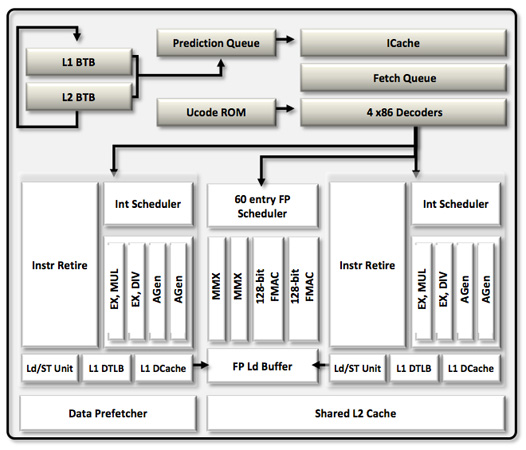 ,بزرگترین تغییر این قسمت، حذف شدن یک پورت از هسته integer و تشکیل یک ترکیب جدید از دو پورت AGU/ALU است. طبق گفته AMD پورت سوم در Phenom II اکثرا بیاستفاده باقی مانده بود و به همین دلیل در معماری جدید آن را حذف کردند.
,بزرگترین تغییر این قسمت، حذف شدن یک پورت از هسته integer و تشکیل یک ترکیب جدید از دو پورت AGU/ALU است. طبق گفته AMD پورت سوم در Phenom II اکثرا بیاستفاده باقی مانده بود و به همین دلیل در معماری جدید آن را حذف کردند.
انتظار ما این بود که هرچقدر ساختارهای تغذیهکننده هستههای integer بزرگتر میشود، AMD بتواند استفاده بیشتری از آنها ببرد. AMD روی کاعذ موفق عمل کرد و توانست عملیاتهای integer بیشتری نسبت به Phenom II اجرا کند هر چند هنوز برای آن محدودهای قائل میشود.,هستههای FP مشترک,هر ماژول «بولدوزر» میتواند برای حداکثر دو بند، یک هسته FP داشته باشد. یعنی این که اگر تنها یک بند FP موجود بود، برای اجرای آن سختافزار اجرای FP اجازه دارد از تمام توانش استفاده کند اما در غیر این صورت باید منابع خود را بین دو بند به اشتراک بگذارد.,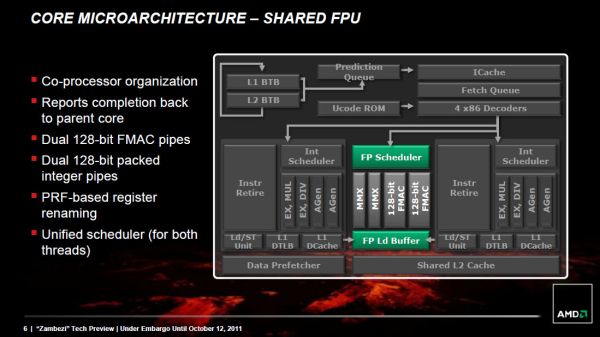 ,علی رغم 8 هستهای بودن «بولدوزر»، این پردازنده هیچ کم و کاستی در زمینه اجرای منابع floating points، نسبت به Phenom II چهار هستهای ندارد. همیشه معماریهای AMD دارای سختافزار «زمانبندی» مستقلی برای دستورات integer و FP بودهاند و این بار میبینیم که تعداد پورتهای سختافزار «اجرا» هم، بین این دو پردازنده، برابر است. نیاز به ذکر نیست که همانند هستههای integer، سختافزار «زمانبندی» هستههای FP هم بزرگتر از قبل شده است.,AAA.png,AMD میدانست که با کوچ به «بولدوزر» باید مصرف واحد FP را بالاتر ببرد. از طرفی چون معماری Phenom II از فقدان SSE4 و AVX رنج میبرد، پشتیبانی از این دو و همچنین fused multiply-add instructions) FMA) را به «بولدوزر» اضافه کرد. با اضافه کردن FMA مساحت قسمت مربوط به واحد FP هم افزایش پیدا کرد. پس با این که بازده این واحد افزایش پیدا نکرد، اما تواناییهای جدیدی بدست آورد ولی متاسفانه همچنان باید همان حجم کار را در x87/SSE2/3 انجام دهد. «بولدوزر» تنها وقتی سریعتر میشود که یا از تکنولوژی SSE، AVX یا FMA جدیدتری استفاده کند و یا سرعت کلاک خود را نسبت به Phenom II خیلی بالاتر ببرد.
,علی رغم 8 هستهای بودن «بولدوزر»، این پردازنده هیچ کم و کاستی در زمینه اجرای منابع floating points، نسبت به Phenom II چهار هستهای ندارد. همیشه معماریهای AMD دارای سختافزار «زمانبندی» مستقلی برای دستورات integer و FP بودهاند و این بار میبینیم که تعداد پورتهای سختافزار «اجرا» هم، بین این دو پردازنده، برابر است. نیاز به ذکر نیست که همانند هستههای integer، سختافزار «زمانبندی» هستههای FP هم بزرگتر از قبل شده است.,AAA.png,AMD میدانست که با کوچ به «بولدوزر» باید مصرف واحد FP را بالاتر ببرد. از طرفی چون معماری Phenom II از فقدان SSE4 و AVX رنج میبرد، پشتیبانی از این دو و همچنین fused multiply-add instructions) FMA) را به «بولدوزر» اضافه کرد. با اضافه کردن FMA مساحت قسمت مربوط به واحد FP هم افزایش پیدا کرد. پس با این که بازده این واحد افزایش پیدا نکرد، اما تواناییهای جدیدی بدست آورد ولی متاسفانه همچنان باید همان حجم کار را در x87/SSE2/3 انجام دهد. «بولدوزر» تنها وقتی سریعتر میشود که یا از تکنولوژی SSE، AVX یا FMA جدیدتری استفاده کند و یا سرعت کلاک خود را نسبت به Phenom II خیلی بالاتر ببرد.
کافیست به این نمودار Cinebench 11.5 نگاه کنیم تا از این عملکرد نوسانی در حجمهای Multi-threaded (چند بندی) مطمئن شویم:,BBB.png,همانطور که در نمودار بالا مشخص است، علی رغم افزایش 9درصدی سرعت پایه کلاک (که با حساب کردن هسته turbo بیشتر هم میشود) این پردازنده 8 هستهای تنها 2٪ بالاتر از Phenom II شش هستهای بهتر عمل میکند. با این اوصاف پردازنده Phenom II برتری مشخصی در این تست داشته است و نشان داد که 50٪ بهتر از «بولدوزر» میتواند دستورات SSE2/3 و x87 را اجرا کند.
از زمان عرضه Phenom II X6 پیشرفت عمده AMD در workloadهای سنگین، به خصوص در FP بوده است. در حقیقت «بولدوزر» یک قدم رو به عقب محسوب میشود و در نتیجه میبینیم که در حجمهای ثابت کار، اگر نسبت به Phenom II X6 یکسان عمل نکند، حتما ضعیفتر از آن خواهد بود.
و اگر با Sandy bridge مقایسه کنیم «بولدوزر» فقط 2 برتری در عملکرد FP دارد: یکی پشتیبانی از FMA و دیگری بازده بیشتر در 128Bit AVX. هرچند که دیگر کدهای بسیار کمی هستند که از دستورات FMA استفاده میکنند، اما نمیشود از ابهت128bit AVX گذشت.
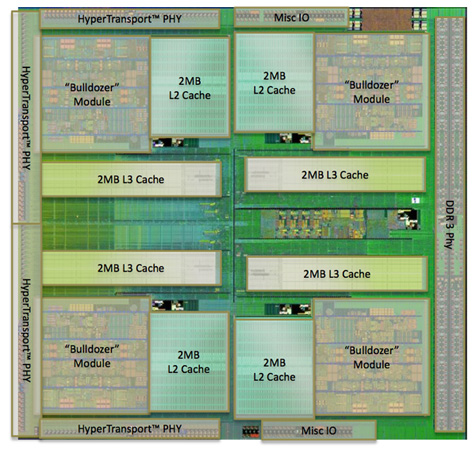
,سلسله مراتب Cache و زیرمجموعههای حافظه,هر هسته integer یک حافظه سطح L1 دارد و هسته مشترک FP حجم loadها و storeهای (موجودیهای) خود را از طریق یکی از این دو هسته integer ارسال میکند؛ مثل طرز کار Phenom II اما با این تفاوت که اینجا به جای یک هسته، از دو هسته integer استفاده میشود. «بولدوزر» حال میتواند load و storeهای کاملا از کار افتاده را دوباره فعال کند و از این نظر نسبت به Phenom II و معماریهای Intel پیشرفت کرده است. در این پردازنده، Instruction cache سطح L1 و L2 با کل ماژول به اشتراک گذاشته شده است.
Instruction cache یک حافظه بزرگ 64KB است که از نظر اندازه شبیه به اندازه حافظه سطح L1 پردازنده Phenom II است ولی در «بولدوزر» توسط هستههای بیشتری به اشتراک گذاشته شده است. پردازنده Phenom II چهار هستهای مقدار 256KB حافظه سطح L1 داشت اما حالا هر 4 هسته «بولدوزر» تنها نصف این مقدار را دارند. همچنین حافظه دادهای «بولدوزر» بسیار کمتر از پیشینیان خود است، برای مثال Phenom II یک D-Cache با 64KB برای هر هسته داشت اما بولدوزر این مقدار را به 16KB کاهش داده است.,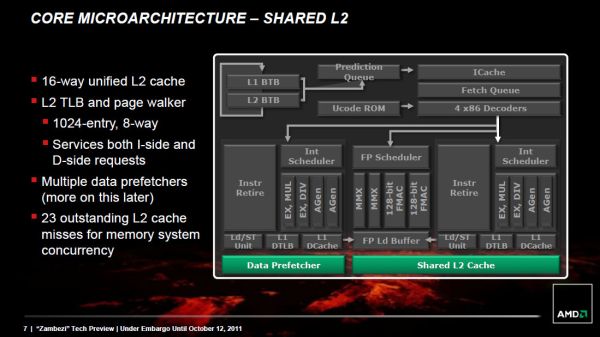 ,همانطور که در تصویر هم مشخص است، حافظه سطح L2 نیز بسیار بزرگتر از طراحیهای Phenom II شده است و هر ماژول «بولدوزر» 2MB حافظه سطح L2 اختصاصی برای خود دارد.
,همانطور که در تصویر هم مشخص است، حافظه سطح L2 نیز بسیار بزرگتر از طراحیهای Phenom II شده است و هر ماژول «بولدوزر» 2MB حافظه سطح L2 اختصاصی برای خود دارد.
همچنین یک حافظه 8MB سطح L3 نیز وجود دارد که در هر چیپ، بین تمام ماژولها تقسیم شده است. در تجسم اولیه AMD، قرار بود که تمام قطعات desktop با حافظه سطح L3 عرضه شوند. هرچند AMD نشان داد که حافظه سطح L3 تنها برای Server Workloads مفید است و بنابراین ممکن است در آینده فقط در محصولات جانبی «بولدوزر» استفاده شود و زمینه را برای حذف کامل آن فراهم کند.
, ,اما برای بیشتر شدن دسترسیهای حافظه موقت، AMD قصد دارد که سرعت کلاک «بولدوزر» را بسیار بالاتر ببرد …,به دنبال سرعت Clock بالاتر,به دنبال سرعت Clock بالاتر,تا اینجا چندین منبع «بولدوزر» را برشمردیم اما تعداد آنها نسبت به فراوانی منابعی که در Phenom II دیدیم، بسیار پایینتر آمده است. بسیاری از این جایگزینیها و حذفها برای این انجام شده است که ضمن اضافه کردن قابلیتهای جدید، مساحت چیپ را ثابت نگه دارند. (برای مثال عریض کردن Front end، بزرگ شدن ساختار دادهها و صفها، پشتیبانی از دستورات جدید) از front end «بولدوزر» گرفته تا Execution Clusterها (واحدی برای ذخیرهسازی دادهها) همه برای قویتر شدن نیاز دارند که سرعت کلاک و تاثیرگذاری آن بالاتر برود. از طرفی «بولدوزر» میدانست که باید بهتر از Phenom II از منابع استفاده کند، در نتیجه اهمیت بالا رفتن سرعت کلاک بیش از پیش شد.
,اما برای بیشتر شدن دسترسیهای حافظه موقت، AMD قصد دارد که سرعت کلاک «بولدوزر» را بسیار بالاتر ببرد …,به دنبال سرعت Clock بالاتر,به دنبال سرعت Clock بالاتر,تا اینجا چندین منبع «بولدوزر» را برشمردیم اما تعداد آنها نسبت به فراوانی منابعی که در Phenom II دیدیم، بسیار پایینتر آمده است. بسیاری از این جایگزینیها و حذفها برای این انجام شده است که ضمن اضافه کردن قابلیتهای جدید، مساحت چیپ را ثابت نگه دارند. (برای مثال عریض کردن Front end، بزرگ شدن ساختار دادهها و صفها، پشتیبانی از دستورات جدید) از front end «بولدوزر» گرفته تا Execution Clusterها (واحدی برای ذخیرهسازی دادهها) همه برای قویتر شدن نیاز دارند که سرعت کلاک و تاثیرگذاری آن بالاتر برود. از طرفی «بولدوزر» میدانست که باید بهتر از Phenom II از منابع استفاده کند، در نتیجه اهمیت بالا رفتن سرعت کلاک بیش از پیش شد.
معمارهای AMD میخواستند که تعداد gateهای کمتری در هر pipeline stage به وجود آورند، زیرا با کاهش این مقدار، زمان کمتری در هر stage گذرانده میشود و در نتیجه فرکانس پردازنده بالاتر میرود. اگر این طرح به گوش شما آشنا است، به این خاطر است که دلیل Intel برای ساخت Pentium 4 نیز همین بود.
اما تفاوت «بولدوزر» در این است که طراحی AMD برعکس P4 سرسختانه برای افزایش فرکانس تلاش نمیکند، بلکه تنها به دنبال کاهش تعداد Gateهای هر stage است. طبق گفته AMD، سیستم سابق باعث بروز مشکلاتی در مدیریت مصرف انرژی میشد اما این سیستم راحتتر کنترل میشود.
به نظر میرسد هدف «بولدوزر» رشد 30درصدی نسبت به فرکانس پردازندههای نسل قبل بود. اما متاسفانه صحت و سقم این گفته، در هالهای از ابهام است و AMD اصلا تایید نمیکند. یعنی طبق این گفته، اگر فرکانس 3.3GHz پردازنده Phenom II X6 را 30٪ بالاتر ببریم، «بولدوزر» باید به فرکانس 4.3GHz برسد.
اما متاسفانه پردازندههای سری FX در 4.3GHz عرضه نخواهند شد. بهترین فرکانسی که ما توانستیم بگیریم، 3.6GHz بود؛ یعنی یک افزایش ناچیز 9 درصدی به ازای یک معماری جدید. هسته Turbo توانست AMD را به اهدافش نزدیک کند، اما معمولا این افزایش فرکانس، مقطعی است.
شاید دوران Pentium 4 و درسی که از آن گرفتیم را به خاطر داشته باشید؛ یک pipeline عمیقتر میتواند عوارض قابلتوجهی با خود داشته باشد. میخواهیم 2 مثال از پردازندههایی برای شما بیاوریم که طول pipeline را فراتر از رقیبان خود برده بودند: Willamette و Prescott.
Willamette سعی داشت که با دو برابر کردن طول pipeline پردازنده P6 (پردازنده نسل ششم Intel)، هم pipeline را کامل کند و هم سرعت کلاک را افزایش دهد. سیاست Willamette این بود که اگر تعداد چرخههای طیشده در هر کلاک پایین آمد، برای جبران این ضربه چرخههای بیشتری ایجاد کنید. Willamette با این که در سرعت کلاک بالاتری کار میکرد و معماری P6 را شکست داد، اما در نهایت تبدیل به دروازهای برای پیشرفت تکنولوژی پردازش شد. دوران Willamette با عرضه پردازنده Northwood توسط خود Intel پایان یافت زیرا این دفعه سرعت کلاک Northwood برای فاصله گرفتن با رقبا کافی بود.
Prescott هم طول pipeline را بیشتر کرد، اماIntel این بار کاملا حسابشده عمل کرد. به خاطر معماری هوشمندانه Intel، این پردازنده توانست تعداد دستورات اجرا شده در هر کلاک را ثابت نگه دارد و به Prescott اجازه داد که فرکانس خود را بالاتر ببرد. تمام این عوامل دست به دست هم دادند تا سرنوشت Prescott را تغییر و از شکستی سریع نجات دهند. اما Prescott از مصرف بالای برق خود ضربه خورد. اجرا در فرکانس خیلی بالا، ولتاژ بسیار زیادی میطلبید و در نتیجه، مصرف برق Prescott سر به فلک کشید.
هدف AMD از «بولدوزر» این بود که IPC (تعداد دستورات اجرا شده در هر کلاک) را ثابت نگه دارد و در عین حال، فرکانس را بالا ببرد، درست مثل Prescott. اگر IPC ثابت بماند، کوچکترین افزایش فرکانس، عملکرد پردازنده را ارتقا میبخشد. اما AMD برای نیل به این هدف، تغییرات دیگری نیز انجام داد: Front end عریضتر شد، ساختار دادههای داخل چیپ بزرگتر شد و execution pathها در هر هسته بیشتر شدند. از بسیاری از جهات «بولدوزر» موفق بود، هرچند تک منظوره بودن آن، باعث شد که ضعیفتر از Phenom II به چشم بیاید:,OVER.png,طبق نتایج نمودار Cinebench، در یک سرعت کلاک یکسان، Phenom II حدود 7٪ سریعتر از «بولدوزر» است. علی رغم تمام تلاشهایی که AMD برای افزایش IPC انجام داد، مقدار IPC پایین رفت.
بخش کوچکی از این نزول، به خاطر صعود فرکانس پردازنده بود. متاسفانه به نظر میرسد که AMD نتوانست سرعت کلاکی که برای «بولدوزر» پیشبینی کرده بود، عملی سازد.,مدیریت مصرف برق و هسته Turbo,مدیریت مصرف برق و هسته Turbo,همانند سری Llano، «بولدوزر» نیز عمدا سرعت کلاک و تکنیک Power gating را در هم آمیخت. Power Gating مقدار برق مصرفی تک هستههای بیکار را تا نزدیک صفرکاهش میدهد و فضا را برای هستههای فعال باز میکند تا بتوانند مفیدتر و در فرکانس بالاتری کار کنند. Intel به این سرعت کلاک پویا ولی متعادل Turbo Boost میگوید اما AMD از آن به نام Turbo Core یاد میکند.
پردازنده Phenom II X6 از یک مدل اولیه turbo core شروع کرد که power gating نداشت و به همین دلیل، turbo core در آن پردازندهها به سختی و به ندرت فعال بود و همین فعالیت تنها برای مدت کوتاهی پایدار بود.
Turbo core «بولدوزر» بسیار قویتر شده است؛ با این که هنوز از روش تخمین مصرف Llano استفاده میکند (مثلا میداند که X واحد محاسبات ALU مصرف برقی معادل Y وات دارد) اما کماکان نتایج باید از بهترین پردازندههای AMD نیز ملموستر باشد. ,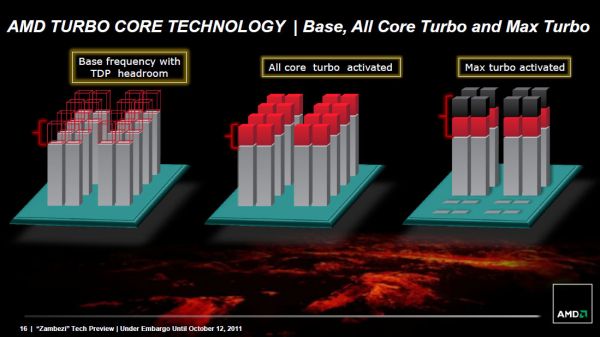 ,محدودهبندیهای Turbo Core در «بولدوزر» نیز حفظ شدهاند. اگر نصف (یا کمتر) هستههای پردازنده فعال باشند، اجازه استفاده از Max Turbo داده میشود. اگر هستههای دیگری هم فعال باشند، Turbo ضعیفتری انتخاب میشود. فقط این دو فرکانس هستند که بالای فرکانس اولیه قرار دارند.
,محدودهبندیهای Turbo Core در «بولدوزر» نیز حفظ شدهاند. اگر نصف (یا کمتر) هستههای پردازنده فعال باشند، اجازه استفاده از Max Turbo داده میشود. اگر هستههای دیگری هم فعال باشند، Turbo ضعیفتری انتخاب میشود. فقط این دو فرکانس هستند که بالای فرکانس اولیه قرار دارند.
AMD در حال حاضر ابزار monitoring مناسبی برای Turbo Core ندارد، پس ما برای ثبت فرکانس پردازنده، حین اجرای دستورات مختلف، به برنامه Core temp روی آوردیم تا تاثیر Turbo Core روی «بولدوزر» را حساب و با Phenom II X6 و Sandy Bridge مقایسه کنیم.
بیاید ابتدا از یک workload پیچیده شروع کنیم، بنچمارک x264 HD. آزمایشهای نرمافزار x264 از دو بخش تشکیل شده است: یک بخش ساده که ویدئو در آن فقط تحلیل میشود و یک بخش پیچیده که کدگذاری واقعی در آن انجام میشود. آزمایش ما 4 مرحله انجام میشود و فرکانس Core 0 در آن اندازهگیری میشود.
اولین شرکتکننده آزمایش، پردازنده Phenom II X6 1100T است. به طور طبیعی 1100T باید در 3.3GHz اجرا شود، اما اگر نصف (یا کمتر) هستهها فعال باشند، میتواند با Turbo به 3.7GHz برسد. اگر Turbo core به خوبی عمل کند، حدس می زنیم که در بخش آسان آزمایش، به بالاتر از 3.7GHz نیز برسد:,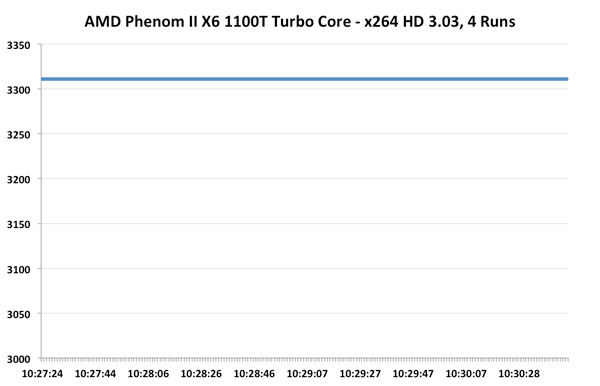 ,متاسفانه انتظارات ما به هیچوجه برآورده نشد. Turbo core در Phenom II X6 تقریبا غیرفعال به نظر میرسد، حداقل در این آزمایش که این طور به نظر میرسد. سرعت کلاک متوسط مقدار ناچیز 3.31GHz را دارد که تنها اندکی بیشتر از مقدار معمول است.
,متاسفانه انتظارات ما به هیچوجه برآورده نشد. Turbo core در Phenom II X6 تقریبا غیرفعال به نظر میرسد، حداقل در این آزمایش که این طور به نظر میرسد. سرعت کلاک متوسط مقدار ناچیز 3.31GHz را دارد که تنها اندکی بیشتر از مقدار معمول است.
حال نوبت به نتایج FX-8150 با Turbo core رسیده است. روی کاغذ، سرعت کلاک پایه 3.6GHz است و با max turbo به 4.2GHz میرسد و مقدار سرعت با Turbo متوسط، 3.9GHz است:,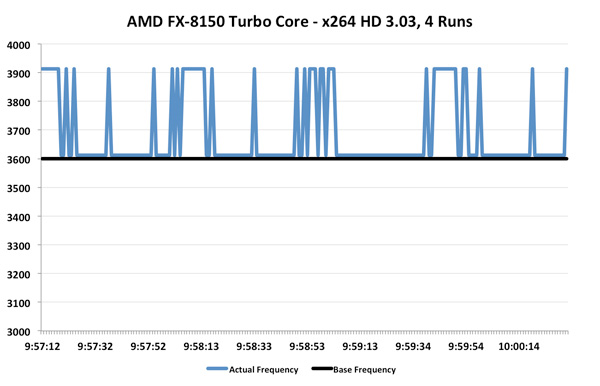 ,نتایج به انتظارات ما نزدیک بود. سرعت میانگین 3.69GHz شده است (2.5٪ بیشتر از حالت بدون Turbo) و نمودار تناوب بالایی دارد. این workload بطور اخص برای هر پردازنده ای و آنطور که خواهیم دید Intel 2500K هم بسیار سنگین به نظر میرسد:,
,نتایج به انتظارات ما نزدیک بود. سرعت میانگین 3.69GHz شده است (2.5٪ بیشتر از حالت بدون Turbo) و نمودار تناوب بالایی دارد. این workload بطور اخص برای هر پردازنده ای و آنطور که خواهیم دید Intel 2500K هم بسیار سنگین به نظر میرسد:,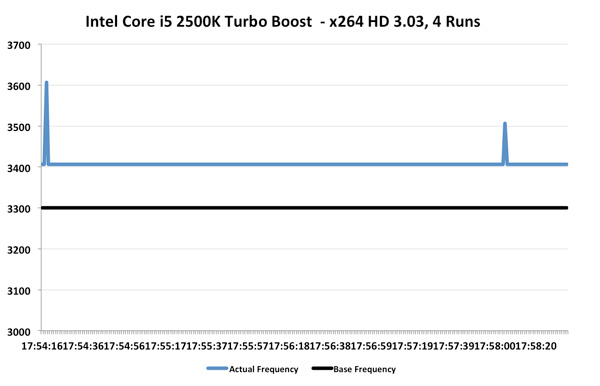 ,2500K به طور طبیعی در 3.3GHz اجرا میشود، اما در این آزمایش، به خاطر وجود Turbo، میانگین سرعت به 3.41GHz رسیده است. حتی در بعضی از موارد شاهد پرش به 3.5 و 3.6GHz نیز هستیم. تکنولوژی Turbo شرکت Intel کمی استوارتر و منظمتر از AMD میباشد اما افزایش سرعت متوسط آن مشابه و حدود 3٪ است.
,2500K به طور طبیعی در 3.3GHz اجرا میشود، اما در این آزمایش، به خاطر وجود Turbo، میانگین سرعت به 3.41GHz رسیده است. حتی در بعضی از موارد شاهد پرش به 3.5 و 3.6GHz نیز هستیم. تکنولوژی Turbo شرکت Intel کمی استوارتر و منظمتر از AMD میباشد اما افزایش سرعت متوسط آن مشابه و حدود 3٪ است.
اجازه دهید به بهترین مورد سناریوی Turbo نگاهی داشته باشیم، یک برنامه شدیدا تک بندی یا Single Threaded، برنامهای که تنها یک خواسته دارد. جایی که مدهای Turbo واقعا می توانند خودی نشان دهند. Turbo کمک میکند که برنامه سریعتر بارگذاری شود، پنجرهها سریعتر باز شوند و workloadهای پیوسته راحتتر اجرا شوند.
ما دوباره به سراغ benchmark مورد علاقه خود، یعنی Cinebench 11.5 رفتهایم. از Phenom II X6 1100T شروع میکنیم:,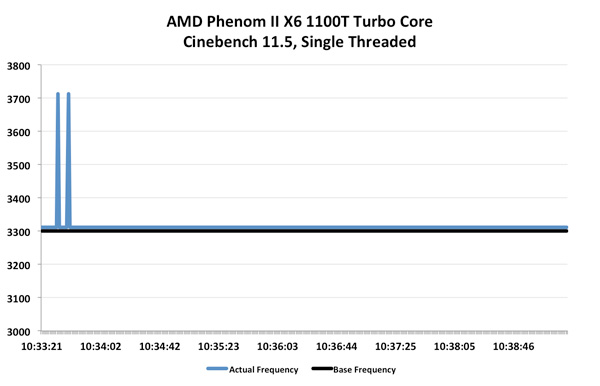 ,Turbo Core روی Phenom II X6 در واقع عمل میکند ولی مدت آن بسیار کوتاه است. با این که نمودار چند جهش کوچک به 3.7GHz دارد اما اکثر اوقات روی 3.3GHz ثابت است. بار دیگر سرعت کلاک متوسط 3.31GHz شده است.
,Turbo Core روی Phenom II X6 در واقع عمل میکند ولی مدت آن بسیار کوتاه است. با این که نمودار چند جهش کوچک به 3.7GHz دارد اما اکثر اوقات روی 3.3GHz ثابت است. بار دیگر سرعت کلاک متوسط 3.31GHz شده است.
«بولدوزر» بسیار بهتر عمل میکند:,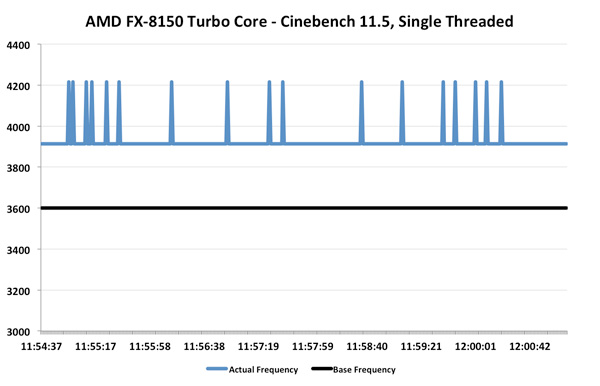 ,اینجا جهشها به سمت 4.2GHz میباشد و نمودار روی 3.9GHz ثابت شده است. سرعت کلاک متوسط 3.93GHz و حدود 9٪ بالاتر از سرعت پایه FX-8150 است.,
,اینجا جهشها به سمت 4.2GHz میباشد و نمودار روی 3.9GHz ثابت شده است. سرعت کلاک متوسط 3.93GHz و حدود 9٪ بالاتر از سرعت پایه FX-8150 است.,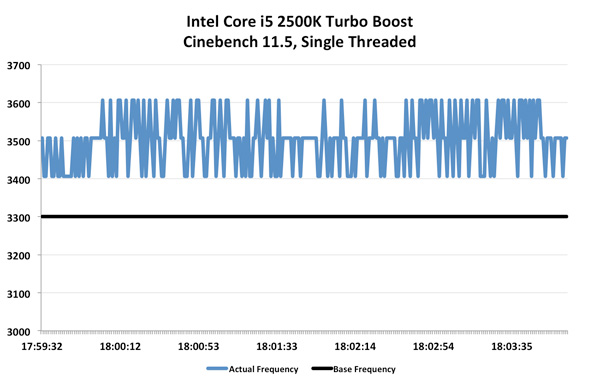 ,Turbo در اینجا پرنوسانتر ظاهر شده است و مقدار آن، به خاطر محدودیتهای TDP، بین 3.4 تا 3.6GHz میچرخد. سرعت کلاک متوسط روی 3.5GHz باقی میماند و 6٪ پیشرفت داشته است. برای اولین بار، AMD در زمینه فرکانس Turbo بهتر از Intel عمل میکند. با این که ما منتظر بودیم که Turbo را محدودتر ببینیم، اما واضح است که Turbo core یکی از شاخصههای اصلی «بولدوزر» است و از نقصهای Phenom II X6 خبری نیست. عملکرد Turbo core در چندین benchmark را در زیر مشاهده میکنید:,
,Turbo در اینجا پرنوسانتر ظاهر شده است و مقدار آن، به خاطر محدودیتهای TDP، بین 3.4 تا 3.6GHz میچرخد. سرعت کلاک متوسط روی 3.5GHz باقی میماند و 6٪ پیشرفت داشته است. برای اولین بار، AMD در زمینه فرکانس Turbo بهتر از Intel عمل میکند. با این که ما منتظر بودیم که Turbo را محدودتر ببینیم، اما واضح است که Turbo core یکی از شاخصههای اصلی «بولدوزر» است و از نقصهای Phenom II X6 خبری نیست. عملکرد Turbo core در چندین benchmark را در زیر مشاهده میکنید:,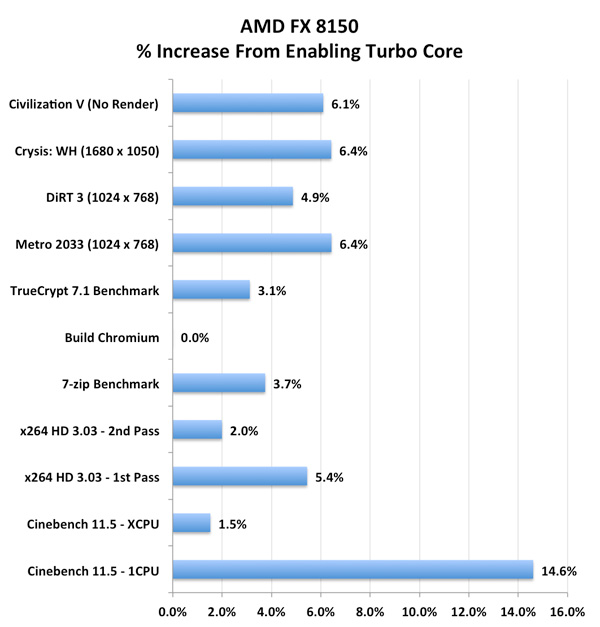 ,میانگین عملکرد در آزمایشهای ما، 5٪ بیشتر شده است. با این که نتایج، عالی نیست اما نوید یک شروع را میدهد. یادمان نرود که عملکرد Turbo Boost هم در اولین معماریهای Intel Core در بهترین حالت متوسط بود. ما امیدواریم که در نسلهای آینده، مشتقات «بولدوزر» بتوانند هرچه بیشتر از Turbo core استفاده کنند.,تاثیر pipeline جدید بولدوزر,تاثیر pipeline جدید بولدوزر,عرضه معماری جدید branch predictor به همراه یک pipeline عمیقتر باعث شد که اشتیاق ما برای پی بردن به جایگاه «بولدوزر» در ماموریت افزایش فرکانس AMD، بیشتر شود. برای همین به سراغ آزمایش N-Queens رفتیم تا نتایج را با نمودار AIDA64 برای شما نشان بدهیم.
,میانگین عملکرد در آزمایشهای ما، 5٪ بیشتر شده است. با این که نتایج، عالی نیست اما نوید یک شروع را میدهد. یادمان نرود که عملکرد Turbo Boost هم در اولین معماریهای Intel Core در بهترین حالت متوسط بود. ما امیدواریم که در نسلهای آینده، مشتقات «بولدوزر» بتوانند هرچه بیشتر از Turbo core استفاده کنند.,تاثیر pipeline جدید بولدوزر,تاثیر pipeline جدید بولدوزر,عرضه معماری جدید branch predictor به همراه یک pipeline عمیقتر باعث شد که اشتیاق ما برای پی بردن به جایگاه «بولدوزر» در ماموریت افزایش فرکانس AMD، بیشتر شود. برای همین به سراغ آزمایش N-Queens رفتیم تا نتایج را با نمودار AIDA64 برای شما نشان بدهیم.
مسئله N-Queens بسیار ساده است. در یک صفحه N x N شطرنج، چگونه N مهره وزیر را قرار دهیم، به شرطی که هیچکدام از این مهرهها نتوانند به یکدیگر حمله کنند؟ چون حل این مسئله نیازمند یک branch قدرتمند است، پس میتواند معیار خوبی برای آزمایش pipeline عمیق باشد.
فرآیند اجرای مسئله N-Queens در برنامه AIDA64 بسیار پیچیده است، اما چون میخواستیم که نگاهی به عملکرد تکهستهای «بولدوزر» هم داشته باشیم، تمام هستهها به غیر از یک هسته integer/fp را غیرفعال کردیم. البته قصد داشتیم که با این کار، ثبات فرکانس و سرعت turbo را هم بررسی کنیم:,4787455555.png,متاسفانه وضعیت خوب نیست؛ حتی با وجود فعال بودن turbo، «بولدوزر» باید 25٪ فرکانس خود را افزایش دهد تا به پای Phenom II X6 برسد. حتی Phenom II X4 با 3.3GHz بهتر عمل میکند. چون اطلاعاتی از نحوه بهینهسازی AIDA64 نداشتیم، سعی کردیم که زیاد بر روی عملکرد Sandy Bridge تمرکز نکنیم، به هرحال Intel همیشه در دقت ساخت branch predictor مشهور بوده است.
اگر تعداد بندهای مسئله N-Queens را بیشتر کنیم، مشکلات عملکرد پردازنده، بهراحتی خود را پشت تعداد زیاد بندها پنهان میکنند.,6666666.png,بدین ترتیب، مشخص شد که وقتی نوبت به اجرای عملیات ساده یا تک بندی اما با انشعابهای زیاد میرسد، «بولدوزر» میتواند از آبروی AMD محافظت کند.,عملکرد Cache و Memory,عملکرد Cache و Memory,قبلا اشاره کردیم که برای تطبیق حافظههای موقت بزرگتر با یکدیگر (یک حافظه 8MB سطح L2 و یک حافظه 8MB سطح L3) و بالا بردن فرکانس، latency (تاخیر در اجرای یک فعالیت) حافظه موقت بیشتر از قبل شده است. برای اندازه گرفتن latency در سرعت کلاک، از جدول cache-mem کمک گرفتیم: ,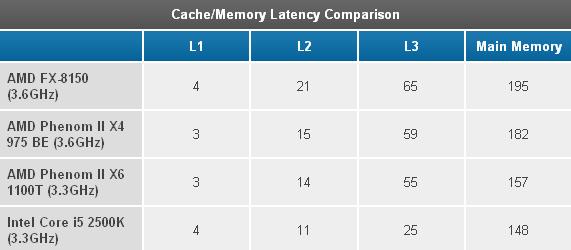 ,همانطور که مشاهده میکنید، Latency حافظه موقت بسیار زیاد شده است، البته به خاطر اعمال تغییرات جدید یعنی عمیق شدن pipeline و بزرگ شدن حافظه موقت، بروز این مشکل دور از انتظار نبود. اما آیا «بولدوزر» میتواند در کلاکهای بالاتر بر این مشکل غلبه کند؟ برای کشف پاسخ باید latency در سرعت کلاک را در نانوثانیه مقایسه کنیم:,44.png,برای رسیدن به سرعت کلاک مورد انتظار، Turbo را خاموش کردیم و توانستیم که latency حافظه را دقیقا محاسبه کنیم. نتایج FX-8150 در این قسمت هم ضعیفتر از پیشینیان آن جلوه میکند. latency بالای حافظه موقت، نقش بسزایی در این شکست ایفا میکند. حتی با فرض استفاده از turbo و رسیدن «بولدوزر» به 3.9GHz، باز هم تاثیر latency کاهشیافته بقدری نیست که از sandy bridge جلو بزند. اما حداقل تاثیر turbo core برای بالا بردن «بولدوزر» از phenom II کافی است.,45.png,در نمودار latency حافظه سطح L3، وضعیت «بولدوزر» نسبت به phenom II بهتر به نظر میرسد زیرا به خاطر فعال شدن Turbo core به سرعت کلاک بیشتری دست پیدا کرده است. از طرفی «بولدوزر» هنوز خیلی کار دارد تا بتواند در حد و اندازه Sandy bridge ظاهر شود.,عملکرد در بازیها,عملکرد در بازیها,AMD آشکارا در راهنمای بررسی کنندگان این پردازنده عنوان کرد که عملکرد پردازنده در بخش Gaming و مخصوصا برنامه های CPU Bound (برنامه هایی که پردازنده گلوگاه سرعت آنها می شود) نقطه قوت سری FX نخواهد بود. با این وجود میخواهیم نگاهی به عملکرد CPU Bound و GPU Bound (برنامه هایی که کارت گرافیک عامل محدودیت سرعت آن است) داشته باشیم و قدرت پردازنده در اجرای workload بازیهای جدید را بررسی کنیم:,Civilization V,برای این بازی 2 نمودار lateGameView Benchmark با 2 نمره مجزا خواهیم داشت: یکی از این نمرهها میانگین Frame rate در تمام طول آزمایش است و دیگری بدون انجام render، فقط عملکرد پردازنده را بررسی میکند.,5127971.png,در نمودار Full-render به نظر میرسد که هر 3 پردازنده AMD از رقیب دیرین خود کمی پیشی گرفته اند. قبلا هم دیدهایم که یک پلتفرم کاملا بر دیگری چیره شود و همیشه توضیح اینجور تفاوتها مشکل بوده است. به خصوص که اینها اصلا دلیلی بر سریعتر بودن پردازندههای AMD نیست و عامل این تفاوت ها، فقط GPU Bound یا محدودیت پردازش گرافیکی است.,3675012.png,در نمودار نمرات No-render دقیقا همان چیزی را میبینیم که انتظارش را داشتیم. خوشبختانه در این زمینه FX-8150 کمی از پیشینیان خود سریعتر است اما همچنان عقبتر از Sandy Bridge است.,Crysis: Warhead,3.png,FX-8150 در Crysis Warhead حتی از Phenom IIهای قدیمی هم کندتر است. نیاز به گفتن نیست که Sandy Bridge کماکان پیشتاز است.,Dawn of war II,4.png,DiRT 3,برای درک بهتر عملکرد CPU Bound و GPU Bound از DiRT 3 هم دو بنچمارک گرفتیم. از بخش CPU Bound شروع میکنیم:,6919165.png,همانطور که مشاهده کردید، باز هم FX-8150 ضعیف عمل میکند و پشت سر Phenom II قرار میگیرد. اما عملکرد «بولدوزر» در بخش GPU Bound قابل قبول است.,6.png,Dragon Age,7.png,یک عنوان دیگر برای مقایسه CPU Bound و طبق معمول FX-8150 عقبتر از بقیه است.,Metro 2033,با این که Metro 2033 حتی روی Resolution های پایین هم، بازی سنگینی است، اما عملکرد FX-8150 تقریبا با 2500K برابری میکند.,8489368.png,9.png,RAGE,10.png,World of Warcraft,13.png,سخن آخر,سخن آخر,از بسیاری از جهات، FX-8150 میتواند فاصله بین Phenom II X6 و Intel’s Core i5 2500k را کمتر کند. اگر به «بولدوزر» workload درستی بدهید، میتواند با سریعترین قطعات Sandy bridge رقابت کند. بالاخره AMD پردازنده پیشرفتهای عرضه کرد که میتواند به خوبی از power gating و Turbo core بسیار کارآمد خود استفاده کند، اما متاسفانه باز هم رد پای بعضی از شکایات مشتریان از پردازندههای AMD در چندسال گذشته، دیده میشود: «بولدوزر» بعضی از برنامههای ساده را اصلا اجرا نمیکند و بدتر از آن این که در اجرای بعضی برنامههای پیچیده، پیشرفتهای اعمال شده آنقدر کافی نیست که دارندگان پلتفرم AM3+ را راضی کند. قطعا پردازنده AMD در اکثر موارد توان رقابت دارد، اما همیشه هم اینگونه نیست. همچنین AMD شما را مجبور میکند که بین اجرای خوب دستورات SingleThreaded و دستورات MultiThreaded یکی را انتخاب کنید؛ انتخابی که بیشتر شبیه «شیر یا خط» است و واقعا لازم نبود که با وجود power gating و turbo core چنین محدودیتی ایجاد شود.
,همانطور که مشاهده میکنید، Latency حافظه موقت بسیار زیاد شده است، البته به خاطر اعمال تغییرات جدید یعنی عمیق شدن pipeline و بزرگ شدن حافظه موقت، بروز این مشکل دور از انتظار نبود. اما آیا «بولدوزر» میتواند در کلاکهای بالاتر بر این مشکل غلبه کند؟ برای کشف پاسخ باید latency در سرعت کلاک را در نانوثانیه مقایسه کنیم:,44.png,برای رسیدن به سرعت کلاک مورد انتظار، Turbo را خاموش کردیم و توانستیم که latency حافظه را دقیقا محاسبه کنیم. نتایج FX-8150 در این قسمت هم ضعیفتر از پیشینیان آن جلوه میکند. latency بالای حافظه موقت، نقش بسزایی در این شکست ایفا میکند. حتی با فرض استفاده از turbo و رسیدن «بولدوزر» به 3.9GHz، باز هم تاثیر latency کاهشیافته بقدری نیست که از sandy bridge جلو بزند. اما حداقل تاثیر turbo core برای بالا بردن «بولدوزر» از phenom II کافی است.,45.png,در نمودار latency حافظه سطح L3، وضعیت «بولدوزر» نسبت به phenom II بهتر به نظر میرسد زیرا به خاطر فعال شدن Turbo core به سرعت کلاک بیشتری دست پیدا کرده است. از طرفی «بولدوزر» هنوز خیلی کار دارد تا بتواند در حد و اندازه Sandy bridge ظاهر شود.,عملکرد در بازیها,عملکرد در بازیها,AMD آشکارا در راهنمای بررسی کنندگان این پردازنده عنوان کرد که عملکرد پردازنده در بخش Gaming و مخصوصا برنامه های CPU Bound (برنامه هایی که پردازنده گلوگاه سرعت آنها می شود) نقطه قوت سری FX نخواهد بود. با این وجود میخواهیم نگاهی به عملکرد CPU Bound و GPU Bound (برنامه هایی که کارت گرافیک عامل محدودیت سرعت آن است) داشته باشیم و قدرت پردازنده در اجرای workload بازیهای جدید را بررسی کنیم:,Civilization V,برای این بازی 2 نمودار lateGameView Benchmark با 2 نمره مجزا خواهیم داشت: یکی از این نمرهها میانگین Frame rate در تمام طول آزمایش است و دیگری بدون انجام render، فقط عملکرد پردازنده را بررسی میکند.,5127971.png,در نمودار Full-render به نظر میرسد که هر 3 پردازنده AMD از رقیب دیرین خود کمی پیشی گرفته اند. قبلا هم دیدهایم که یک پلتفرم کاملا بر دیگری چیره شود و همیشه توضیح اینجور تفاوتها مشکل بوده است. به خصوص که اینها اصلا دلیلی بر سریعتر بودن پردازندههای AMD نیست و عامل این تفاوت ها، فقط GPU Bound یا محدودیت پردازش گرافیکی است.,3675012.png,در نمودار نمرات No-render دقیقا همان چیزی را میبینیم که انتظارش را داشتیم. خوشبختانه در این زمینه FX-8150 کمی از پیشینیان خود سریعتر است اما همچنان عقبتر از Sandy Bridge است.,Crysis: Warhead,3.png,FX-8150 در Crysis Warhead حتی از Phenom IIهای قدیمی هم کندتر است. نیاز به گفتن نیست که Sandy Bridge کماکان پیشتاز است.,Dawn of war II,4.png,DiRT 3,برای درک بهتر عملکرد CPU Bound و GPU Bound از DiRT 3 هم دو بنچمارک گرفتیم. از بخش CPU Bound شروع میکنیم:,6919165.png,همانطور که مشاهده کردید، باز هم FX-8150 ضعیف عمل میکند و پشت سر Phenom II قرار میگیرد. اما عملکرد «بولدوزر» در بخش GPU Bound قابل قبول است.,6.png,Dragon Age,7.png,یک عنوان دیگر برای مقایسه CPU Bound و طبق معمول FX-8150 عقبتر از بقیه است.,Metro 2033,با این که Metro 2033 حتی روی Resolution های پایین هم، بازی سنگینی است، اما عملکرد FX-8150 تقریبا با 2500K برابری میکند.,8489368.png,9.png,RAGE,10.png,World of Warcraft,13.png,سخن آخر,سخن آخر,از بسیاری از جهات، FX-8150 میتواند فاصله بین Phenom II X6 و Intel’s Core i5 2500k را کمتر کند. اگر به «بولدوزر» workload درستی بدهید، میتواند با سریعترین قطعات Sandy bridge رقابت کند. بالاخره AMD پردازنده پیشرفتهای عرضه کرد که میتواند به خوبی از power gating و Turbo core بسیار کارآمد خود استفاده کند، اما متاسفانه باز هم رد پای بعضی از شکایات مشتریان از پردازندههای AMD در چندسال گذشته، دیده میشود: «بولدوزر» بعضی از برنامههای ساده را اصلا اجرا نمیکند و بدتر از آن این که در اجرای بعضی برنامههای پیچیده، پیشرفتهای اعمال شده آنقدر کافی نیست که دارندگان پلتفرم AM3+ را راضی کند. قطعا پردازنده AMD در اکثر موارد توان رقابت دارد، اما همیشه هم اینگونه نیست. همچنین AMD شما را مجبور میکند که بین اجرای خوب دستورات SingleThreaded و دستورات MultiThreaded یکی را انتخاب کنید؛ انتخابی که بیشتر شبیه «شیر یا خط» است و واقعا لازم نبود که با وجود power gating و turbo core چنین محدودیتی ایجاد شود.
البته نمیشود از این حقیقت گذشت که معماری «بولدوزر» واقعا جالب است، اما مطمئن نیستیم که چقدر آمادگی دارد. از طرفی کاملا روشن بود که AMD نیاز دارد که برای درخشاندن «بولدوزر» سرعت کلاک بالایی را فراهم کند؛ اما به هر دلیلی که بود، موفق به انجام چنین کاری نشد. خبر عرضه سری Piledriver در سال بعد و مژده افزایش 10 تا 15 درصدی سطح هستهها، این تصور را به وجود میآورد که AMD دارد به نقصهای این سری اشاره میکند. اما تنها نگرانی ما این است که آیا این افرایش 15درصدی، برای کاهش فاصله امروز، کافی است؟ و اگر بخواهیم دقیقتر نگاه کنیم، نگرانی اصلی در مورد اجرای برنامههای ساده است، قسمتی که امروز i5 2500k توانسته به راحتی 40-50 درصد جلوتر باشد. , ,همچنین AMD اعلام کرده است که Windows 7 آنچنان برای «بولدوزر» بهینه نشده است. به خاطر معماری خاص ماژول چندهستهای AMD، OS Scheduler باید بداند چه زمانی بندها را در تکماژولها (با Cache مشترک) یا ماژولهای جداگانه (با Cache اختصاصی) قرار دهد. حال چون Scheduler ویندوز 7 کاملا از معماری «بولدوزر» آگاهی ندارد، در هرجایی که بتواند بندها را قرار میدهد. انتظار است که Windows 8 بتواند این مشکل را اصلاح کند، از طرفی چون با عرضه Windows 8 فاصله داریم، ممکن است یک جایگزین ارتقا یافته از طرف AMD معرفی شود.,
,همچنین AMD اعلام کرده است که Windows 7 آنچنان برای «بولدوزر» بهینه نشده است. به خاطر معماری خاص ماژول چندهستهای AMD، OS Scheduler باید بداند چه زمانی بندها را در تکماژولها (با Cache مشترک) یا ماژولهای جداگانه (با Cache اختصاصی) قرار دهد. حال چون Scheduler ویندوز 7 کاملا از معماری «بولدوزر» آگاهی ندارد، در هرجایی که بتواند بندها را قرار میدهد. انتظار است که Windows 8 بتواند این مشکل را اصلاح کند، از طرفی چون با عرضه Windows 8 فاصله داریم، ممکن است یک جایگزین ارتقا یافته از طرف AMD معرفی شود.,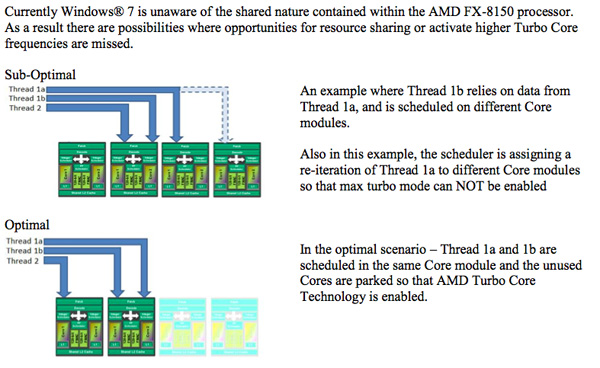 ,اما هنوز یک مسئله بررسی نشده است: اگر شما بخواهید امروز یک پردازنده بخرید، بهتر است کدام را انتخاب کنید؟ اگر شما یک سیستم پیشرفته با Phenom II ترتیب دادهاید، و احتمالا یک پردازنده X4 970 یا بالاتر و یا X6 دارید، من واقعا دلیلی برای ارتقا نمیبینم. اگر شما میخواهید با همین پلتفرم جلو بروید، بهتر است تا عرضه پردازنده بعدی (و پایانی) AM3+ صبر کنید، اما اگر حتما میخواهید پردازنده جدیدی بخرید، احساس میکنم که 2500K بهترین و جامعترین قطعه است. این پردازنده، یک عملکرد باثبات در تمام برنامهها، صرف نظر از نوع و وضعیت workload آنها، به شما میدهد و میتوانید از امکاناتی نظیر Quick Sync استفاده کنید.. در حقیقت، جایی که «بولدوزر» خوب عمل کرده است، همان جایی است که AMD همیشه خوب عمل میکند: نرمافزارهای پیچیده. اگر شما معمولا برنامههایی اجرا میکنید که ساختار بندهای خوبی دارد، «بولدوزر» معمولا عملکردی در سطح 2500K شرکت Intel، یا بالاتر از آن ارائه میدهد.,
,اما هنوز یک مسئله بررسی نشده است: اگر شما بخواهید امروز یک پردازنده بخرید، بهتر است کدام را انتخاب کنید؟ اگر شما یک سیستم پیشرفته با Phenom II ترتیب دادهاید، و احتمالا یک پردازنده X4 970 یا بالاتر و یا X6 دارید، من واقعا دلیلی برای ارتقا نمیبینم. اگر شما میخواهید با همین پلتفرم جلو بروید، بهتر است تا عرضه پردازنده بعدی (و پایانی) AM3+ صبر کنید، اما اگر حتما میخواهید پردازنده جدیدی بخرید، احساس میکنم که 2500K بهترین و جامعترین قطعه است. این پردازنده، یک عملکرد باثبات در تمام برنامهها، صرف نظر از نوع و وضعیت workload آنها، به شما میدهد و میتوانید از امکاناتی نظیر Quick Sync استفاده کنید.. در حقیقت، جایی که «بولدوزر» خوب عمل کرده است، همان جایی است که AMD همیشه خوب عمل میکند: نرمافزارهای پیچیده. اگر شما معمولا برنامههایی اجرا میکنید که ساختار بندهای خوبی دارد، «بولدوزر» معمولا عملکردی در سطح 2500K شرکت Intel، یا بالاتر از آن ارائه میدهد., ,ما امیدوار بودیم که «بولدوزر» به جای تمرکز روی نقطه قوت AMD، نقاط ضعف آنها را نشانه برود. شک داریم که این معماری بتواند به درستی در فضای Server عمل کند، اما برای کامپیوترهای شخصی، بهتر است که مدتی بیشتر صبر کنیم تا AMD قطعه قویتری عرضه کند. واقعا سخت است که نقطه اشتباه «بولدوزر» در برنامههای ساده را پیدا کنیم. سادهترین جواب، سرعت کلاک است، به نظر میرسد که «بولدوزر» قربانی مشکلات داخلی Global Foundries شده است. اگر هدف سرعت کلاک، افزایش 30 درصدی نسبت به Phenom II بود، قطعا با FX-8150 محقق نشده است. شایعاتی مطرح است که در آینده، تمرکز محصولات AMD بیشتر بر روی IPC خواهد بود. اما اگر از من بپرسید برای موفق شدن، چه چیزی را میشود فدا کرد، میگفتم سرعت کلاک. حقیقت بعدی این است که انگار AMD برای انتخاب مساحت 32 نانومتری تردید داشته است. به سختی میتوان «بولدوزر» را یک پردازنده ظریف معرفی کرد. ممکن است که مهاجرت AMD به یک ترانزیستور کوچکتر، بعضی از نقایص فیزیکی «بولدوزر» را مشخص کند.
,ما امیدوار بودیم که «بولدوزر» به جای تمرکز روی نقطه قوت AMD، نقاط ضعف آنها را نشانه برود. شک داریم که این معماری بتواند به درستی در فضای Server عمل کند، اما برای کامپیوترهای شخصی، بهتر است که مدتی بیشتر صبر کنیم تا AMD قطعه قویتری عرضه کند. واقعا سخت است که نقطه اشتباه «بولدوزر» در برنامههای ساده را پیدا کنیم. سادهترین جواب، سرعت کلاک است، به نظر میرسد که «بولدوزر» قربانی مشکلات داخلی Global Foundries شده است. اگر هدف سرعت کلاک، افزایش 30 درصدی نسبت به Phenom II بود، قطعا با FX-8150 محقق نشده است. شایعاتی مطرح است که در آینده، تمرکز محصولات AMD بیشتر بر روی IPC خواهد بود. اما اگر از من بپرسید برای موفق شدن، چه چیزی را میشود فدا کرد، میگفتم سرعت کلاک. حقیقت بعدی این است که انگار AMD برای انتخاب مساحت 32 نانومتری تردید داشته است. به سختی میتوان «بولدوزر» را یک پردازنده ظریف معرفی کرد. ممکن است که مهاجرت AMD به یک ترانزیستور کوچکتر، بعضی از نقایص فیزیکی «بولدوزر» را مشخص کند.
اما خبر خوب این است که AMD یک برنامه روشن و جدی برای آینده خود ترتیب داده است و ما امیدواریم که بتواند به آن عمل کند. همه ما نیاز داریم که AMD موفق شود، چون میدانیم اگر AMD به عنوان یک رقیب قوی جلوه نکند، چه اتفاقاتی میافتد. پردازندههایی عرضه میشود که محدودیتهای ساختگی شدیدی بر روی Overclocking خواهد داشت. ما اصلا شما را مقید به یک انتخاب نمیکنیم زیرا با این کار، جلوی رشد جایگزینها را میگیریم. من هم اعتقاد ندارم که «بولدوزر» یک جایگزین قوی و یک حریف سرسخت برای Intel است، اما ما نیاز داریم که به چنین پردازندهای تبدیل شود. من مطمئن هستم که AMD از پس این کار برمیآید ولی این مسیر، پیشرفت زیادی میطلبد. AMD نمیتواند بر روی برتری GPU خود تکیه کند تا بتواند APUهای خود را بفروشد، باید از سراشیبی x86 نیز عبور کند. در اصل، AMD باید عملکرد خود را در زمینه اجرای برنامههای ساده ارتقا ببخشد؛ «بولدوزر» نتوانست این کار را بکند و نگران هستیم که پیشرفت Piledriver هم کافی نباشد. اما اگر AMD، ریتم پیشرفت سالانه خوبی درست کند، هنوز جای امیدواری هست.
دیگر پرسیدن این که آیا AMD به روزهای خوش Athlon 64 برمیگردد یا خیر، کافی است! AMD باید آن روزها را تکرار کند، وگرنه شما میتوانید با AMD خداحافظی کنید!
منبع:
http://www.anandtech.com,نقد و بررسی پردازنده های AMD-FX,نقد و بررسی پردازنده های AMD-FX,